/** * struct irq_desc - interrupt descriptor * @irq_data: per irq and chip data passed down to chip functions * @kstat_irqs: irq stats per cpu * @handle_irq: highlevel irq-events handler * @preflow_handler: handler called before the flow handler (currently used by sparc) * @action: the irq action chain * @status: status information * @core_internal_state__do_not_mess_with_it: core internal status information * @depth: disable-depth, for nested irq_disable() calls * @wake_depth: enable depth, for multiple irq_set_irq_wake() callers * @irq_count: stats field to detect stalled irqs * @last_unhandled: aging timer for unhandled count * @irqs_unhandled: stats field for spurious unhandled interrupts * @lock: locking for SMP * @affinity_hint: hint to user space for preferred irq affinity * @affinity_notify: context for notification of affinity changes * @pending_mask: pending rebalanced interrupts * @threads_oneshot: bitfield to handle shared oneshot threads * @threads_active: number of irqaction threads currently running * @wait_for_threads: wait queue for sync_irq to wait for threaded handlers * @dir: /proc/irq/ procfs entry * @name: flow handler name for /proc/interrupts output */struct irq_desc { struct irq_data irq_data; unsigned int __percpu *kstat_irqs;///* irq的统计信息,在proc中可查到 */ irq_flow_handler_t handle_irq; /* 回调函数,当此中断产生中断时,会调用handle_irq,在handle_irq中进行遍历irqaction链表*/ /* handle_simple_irq 用于简单处理; * handle_level_irq 用于电平触发中断的流控处理; * handle_edge_irq 用于边沿触发中断的流控处理; * handle_fasteoi_irq 用于需要响应eoi的中断控制器; * handle_percpu_irq 用于只在单一cpu响应的中断; * handle_nested_irq 用于处理使用线程的嵌套中断; */#ifdef CONFIG_IRQ_PREFLOW_FASTEOI irq_preflow_handler_t preflow_handler;#endif struct irqaction *action; /* IRQ action list */ unsigned int status_use_accessors; unsigned int core_internal_state__do_not_mess_with_it; unsigned int depth; /* nested irq disables */ /* 嵌套深度,中断线被激活显示0,如果为正数,表示被禁止次数 */ unsigned int wake_depth; /* nested wake enables */ unsigned int irq_count; /* For detecting broken IRQs *//* 此中断线上发生的中断次数 */ unsigned long last_unhandled; /* Aging timer for unhandled count */ /* 上次发生未处理中断时的jiffies值 */ unsigned int irqs_unhandled;/* 中断线上无法处理的中断次数,如果当第100000次中断发生时,有超过99900次是意外中断,系统会禁止这条中断线 */ raw_spinlock_t lock; struct cpumask *percpu_enabled;#ifdef CONFIG_SMP const struct cpumask *affinity_hint; /* CPU亲和力关系,其实就是每个CPU是占一个bit长度,某CPU上置为1表明该CPU可以进行这个中断的处理 */ struct irq_affinity_notify *affinity_notify;#ifdef CONFIG_GENERIC_PENDING_IRQ cpumask_var_t pending_mask; /* 用于调整irq在各个cpu之间的平衡 */#endif#endif unsigned long threads_oneshot; atomic_t threads_active; wait_queue_head_t wait_for_threads; /* 用于synchronize_irq(),等待该irq所有线程完成 */#ifdef CONFIG_PROC_FS struct proc_dir_entry *dir; /* 指向与IRQn相关的/proc/irq/n目录的描述符 */#endif int parent_irq; struct module *owner; const char *name;/* 在/proc/interrupts所显示名称 */} ____cacheline_internodealigned_in_smp; 中断的描述符如上所述。作为背景知识,可以理解下面的内容,本文讨论基于的内核版本信息如下:
uname -aLinux localhost.localdomain 3.10.0
我们知道,nvme的多队列,默认按照核数的多少来设置,目前nvme的队列有两种,admin队列,IO队列,两者都属于nvme_queue对象,submit queue,complete queue是一个nvme_queue对象的一个成员,其中submit queue在代码中会简写为sq,complete queue会简写成cq。两者是Queue Pair(QP),也就是submitqueue·completequeue和admin queue不是同一个级别的对象,对于admin队列来说,它也有自己的submitquque和completequeue,第一次看代码时往往容易混淆。
首先,我们来看一下nvme总共用的中断数。
# cat /proc/interrupts |grep nvme |wc -l
320该系统上一共4块盘,80个核,就有320个中断,一个核对应一个队列,一个中断号。按道理IOqueue有80个,adminqueue也需要用中断,
那么中断数应该是81*4=324才对。
# cat /proc/interrupts |grep -i nvme[0-3]q0|awk '{print $1,$(NF-1),$NF}'1762: nvme2q0, nvme2q11766: nvme3q0, nvme3q11767: nvme0q0, nvme0q11768: nvme1q0, nvme1q1 我们发现,nvme0q0 和 nvme0q1 是共享中断的。而其他的sq都是虽然带的参数也是共享,但是从实际情况看,是独占的。所以数量是320个。
nvme0q0 就是我们可爱的admin queue,从申请的角度看,我们可以看出来,一开始adminqueue申请,用的是裸命令,后面的ioqueues申请,利用的是admin queue的队列。
由于admin的queue是最先申请的,所以包括中断号也是单独申请的,nvme_configure_admin_queue 中,调用静态函数 queue_request_irq来初始化admin的队列的中断,而且它传入的参数是共享的,也就是不需要独占中断,IRQF_SHARED。admin的队列编号是0。
static int nvme_configure_admin_queue(struct nvme_dev *dev){ int result; u32 aqa; u64 cap = lo_hi_readq(dev->bar + NVME_REG_CAP); struct nvme_queue *nvmeq; dev->subsystem = readl(dev->bar + NVME_REG_VS) >= NVME_VS(1, 1, 0) ? NVME_CAP_NSSRC(cap) : 0; if (dev->subsystem && (readl(dev->bar + NVME_REG_CSTS) & NVME_CSTS_NSSRO)) writel(NVME_CSTS_NSSRO, dev->bar + NVME_REG_CSTS); result = nvme_disable_ctrl(&dev->ctrl, cap); if (result < 0) return result; nvmeq = dev->queues[0];//admin是第一个queue,队列编号肯定是0 if (!nvmeq) { //admin的queue,深度为256 nvmeq = nvme_alloc_queue(dev, 0, NVME_AQ_DEPTH);//2 if (!nvmeq) return -ENOMEM; } aqa = nvmeq->q_depth - 1; aqa |= aqa << 16;//将sq_dma_addr 和 cq_dma_addr 分别系到bar 空间偏移为NVME_REG_ASQ和NVME_REG_ACQ,这个地址都是在nvme_alloc_queue 中申请的. writel(aqa, dev->bar + NVME_REG_AQA); lo_hi_writeq(nvmeq->sq_dma_addr, dev->bar + NVME_REG_ASQ); lo_hi_writeq(nvmeq->cq_dma_addr, dev->bar + NVME_REG_ACQ); result = nvme_enable_ctrl(&dev->ctrl, cap); if (result) return result; nvmeq->cq_vector = 0; result = queue_request_irq(dev, nvmeq, nvmeq->irqname);//为admin队列申请中断,这个是nvme驱动最先申请的中断号 if (result) { nvmeq->cq_vector = -1; return result; } return result;}
而ioquue,都是调用的nvme_pci_enable来完成中断的申请,
中断注册,也是在队列创建的时候完成,nvme_create_queue ,其中需要注意的是,admin的中断,会先注册,然后再取消注册,然后再注册一次。先注册的目的是为了借助这个中断来返回处理创建sq和cq等命令的结果。
nvme_create_io_queues---|nvme_alloc_queue----分配nvmeq结构体,并记录到dev->queues[]数组中,并分配submit queue 和complete queue命令所需要的空间。
---|nvme_create_queue---|adapter_alloc_cq----构建cmd,利用admin 的queue发送控制消息,分配sq相关信息
---|adapter_alloc_sq----这个是分配submitqueue队列的相关信息,与cq类似。
---|queue_request_irq---这个是申请中断
---|nvme_init_queue---初始化队列
下面,重点了解下queue_request_irq 的传入参数:
static int queue_request_irq(struct nvme_dev *dev, struct nvme_queue *nvmeq, const char *name){ if (use_threaded_interrupts)//中断线程化使能,默认没有开启 return request_threaded_irq(dev->entry[nvmeq->cq_vector].vector, nvme_irq_check, nvme_irq, IRQF_SHARED, name, nvmeq); return request_irq(dev->entry[nvmeq->cq_vector].vector, nvme_irq, IRQF_SHARED, name, nvmeq);} static int use_threaded_interrupts;默认就是0了。 也就是nvme驱动默认没有使能中断线程化功能。request_irq 是中断的申请接口了,定义在interrupt.h中,调用request_threaded_irq,其中第三个传入传入的是NULL
static inline int __must_checkrequest_irq(unsigned int irq, irq_handler_t handler, unsigned long flags, const char *name, void *dev){ return request_threaded_irq(irq, handler, NULL, flags, name, dev);} request_threaded_irq定义在manager.c中,后面就是中断的通用流程了,我们主要针对传入的参数分析一下:
int request_threaded_irq(unsigned int irq, irq_handler_t handler, irq_handler_t thread_fn, unsigned long irqflags, const char *devname, void *dev_id){........... action->handler = handler;---------就是我们的nvme_irq action->thread_fn = thread_fn;-----nvme中传入的是NULL action->flags = irqflags; action->name = devname;-------------nvmeq->irqname,中断名称,就是/proc/interrupts每行的最后那列,当中断共享的时候,会显示注册的多个名称。 action->dev_id = dev_id;------------nvmeq,作为对象,会在thread_fn 作为最后一个参数传回来
..... ..... }
static irqreturn_t nvme_irq(int irq, void *data)------处理nvme中断{ irqreturn_t result; struct nvme_queue *nvmeq = data;--------回调nvme_irq的时候,传入的data就是之前注册的时候传入的dev_id spin_lock(&nvmeq->q_lock);-------------由于默认每个队列是在一个cpu上,所以这里自旋锁的消耗很少,是一种无锁设计的保护而已。 nvme_process_cq(nvmeq); result = nvmeq->cqe_seen ? IRQ_HANDLED : IRQ_NONE; nvmeq->cqe_seen = 0; spin_unlock(&nvmeq->q_lock); return result;} 去掉包裹函数,真正干活的就是nvme_process_cq 了,又看到了熟悉的head,tail标志,这个机制的描述在网上已经烂大街了,借用一下:
Head/Tail机制
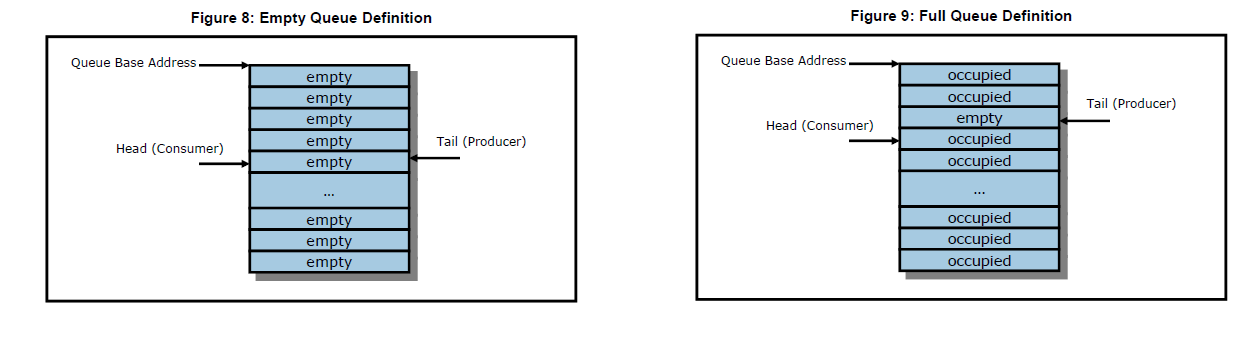
Submission Queue使用Tail,Completion Queue使用Head,两者均由Host操作。处理完一个Command,Tail或Head加1,当大于Queue Depth时,则回到0。通过对比Head和Tail的值,就知道一个Queue中有多少未处理的Submission Command。下面的图摘自NVMe Spec,有兴趣的同学可以据此琢磨下Empty Queue和Full Queue的定义。
static int nvme_process_cq(struct nvme_queue *nvmeq){ u16 head, phase; head = nvmeq->cq_head; phase = nvmeq->cq_phase; while (nvme_cqe_valid(nvmeq, head, phase)) { struct nvme_completion cqe = nvmeq->cqes[head]; struct request *req; if (++head == nvmeq->q_depth) { head = 0; phase = !phase; } if (unlikely(cqe.command_id >= nvmeq->q_depth)) { dev_warn(nvmeq->dev->ctrl.device, "invalid id %d completed on queue %d\n", cqe.command_id, le16_to_cpu(cqe.sq_id)); continue; } /* * AEN requests are special as they don't time out and can * survive any kind of queue freeze and often don't respond to * aborts. We don't even bother to allocate a struct request * for them but rather special case them here. */ if (unlikely(nvmeq->qid == 0 && cqe.command_id >= NVME_AQ_BLKMQ_DEPTH)) { nvme_complete_async_event(&nvmeq->dev->ctrl, cqe.status, &cqe.result); continue; } req = blk_mq_tag_to_rq(*nvmeq->tags, cqe.command_id); nvme_req(req)->result = cqe.result; blk_mq_complete_request(req, le16_to_cpu(cqe.status) >> 1); } if (head == nvmeq->cq_head && phase == nvmeq->cq_phase) return 0; if (likely(nvmeq->cq_vector >= 0)) writel(head, nvmeq->q_db + nvmeq->dev->db_stride); nvmeq->cq_head = head; nvmeq->cq_phase = phase; nvmeq->cqe_seen = 1; return 1;}